Tesseract OCR: Installation and Usage on Ubuntu 16.04
Tesseract is one of the most powerful open source OCR engine available today. OCR stands for Optical Character Recognition. This is the process of extracting texts from images. For example, consider the following image which has some text in it that has to be extracted out:

The Output from the OCR engine, once some processing is done will be something like this:
Open Access Button
This is how OCR works. It is useful in many applications like vehicle number plate recognition, converting scanned copies of documents to word format, automatic extraction of details from receipts, etc. It also forms the first step in many Natural Language Processing tasks. In this tutorial, we will be looking into how to quickly install and setup Tesseract, imagemagick and how to use them to get the best results possible with pre-processing of images.
Image pre-processing is an important part of performing OCR with Tesseract. This ensures that the accuracy of the extracted text is high and reduces the error. We will go through some basic operations to perform on the image using it. Imagemagick is a image processing command line based tool, that helps us to perform operations like cropping, resizing, changing color schemes, etc.
1 Install Tesseract
It is pretty simple to install tesseract, run the following commands:
sudo apt update sudo apt install tesseract-ocr
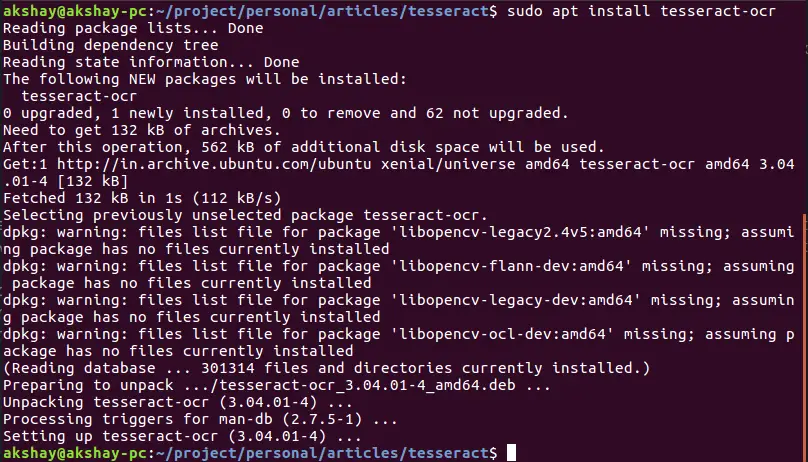
This installs the Tesseract engine. The Image below shows the output when it's installed correctly:
The next thing to do is install the language packs. Tesseract is very robust and it can extract over 100 different languages, provided the language packs are downloaded. You can download a particular language pack by using the generic command below:
sudo apt-get install tesseract-ocr-[lang]
In the above command, replace "[lang]" with the language you want to download. Examples for english and french are below:
sudo apt-get install tesseract-ocr-eng sudo apt-get install tesseract-ocr-fra
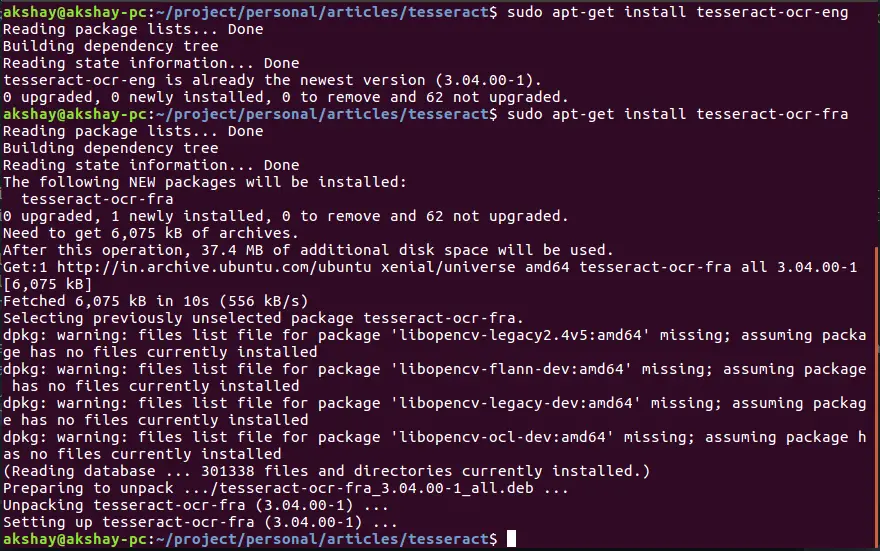
Usually, the tesseract comes with the english pack by default. The image below shows that english was already installed and french had to be downloaded and installed:
Alternatively, if you want all the language packs to be downloaded, you can run the following command:
sudo apt-get install tesseract-ocr-all
This completes Tesseract installation.
2 Install Imagemagick Run the following command to install imagemagick
sudo apt install imagemagick
This tool is used from the command line using the convert command. To check correct installation, run the following command and the output should be similar to the image below:
convert -h
3 Tesseract Usage
Tesseract is capable of taking images of many different formats like jpg, png, tiff, etc and extracting text from it. This section focuses on running tesseract and in the next section, we will see how we can improve accuracy. Here are some basic commands to run tesseract :
To get the output in the terminal, run the generic command with the path of the image
tesseract [image_path] stdout
To store the OCR output to a file run the following generic command:
tesseract [image_path] [file_name]
Following two images, show the image used and the output of running the above to commands on that image

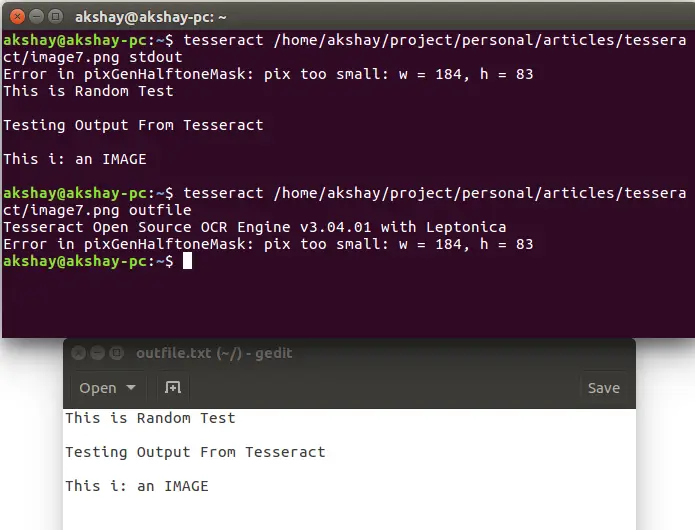
As you can observe, running the second command has led to the creation of a file called "outfile.txt" in which the output can be found.
4 Image pre-processing
From the previous output, you might have observed that, there is an error in the output, and also an error saying that the pixels size is small. This is one of the disadvantages of Tesseract, it expects you to give a processed image that it can perform OCR on. In this section, we will go through some of the tactics you can use with the help of imagemagick to improve the quality of the image and thus increase the accuracy of the output.
4.1 resizing
Resizing is one of the most helpful tricks to improve OCR accuracy. This is because most of time images, have very small font size which cannot be read properly by Tesseract. You can resize an image by using the following command. The percentage amount indicate the resizing limit. Since we want to increase the size, we need to give a value greater than 100. Here, we have given a value of 150% ( use a trial and error method to determine the perfect resizing % for your use case).
convert -resize 150% [input_file_path] [output_file_path]
in the above command, replace the [input_file_path] with the path of the image which has to be resized and [output_file_path] with the path of the image where the output should be stored. The following image is the output when I ran the command: convert -resize 150% image7.png image7_resize.png
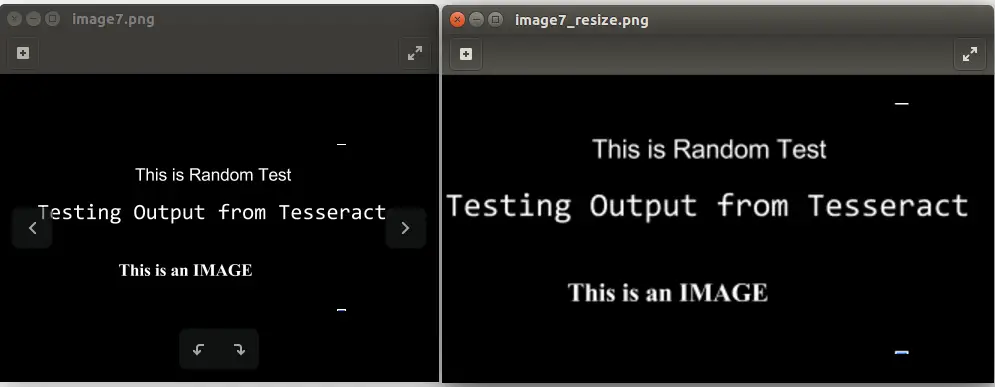
4.2 Use Grayscale Images
If you have a colored image, then it is advised to convert it to grayscale first. There is a good chance that just this will be enough to get the OCR accuracy that you want. Otherwise, to process further, you can use the grayscale images to binarize the image. Use the following command to convert your image to convert it to grayscale
convert [input_file_path] -type Grayscale [output_file_path]
The following image shows the output for running the command convert image6_resize.png -type Grayscale image6_gray.png
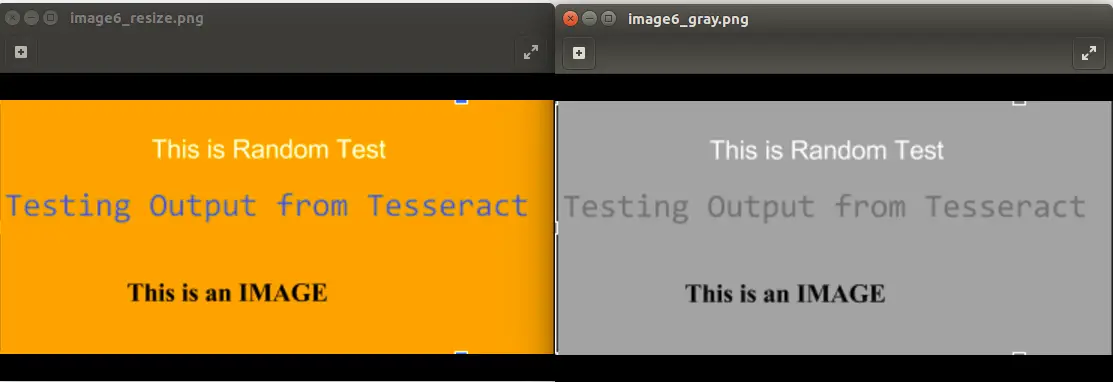
4.3 Binarize the image
Binarization or thresholding involves, converting the image to just values of black and white. Each pixel in this image has only one of two values, either black or white. This reduces the complexity of images drastically. If you have images with noise or images with shadow, or lot of text, you can use this method of preprocessing.To binarize this image, make sure you first have a grayscale image, and then use the following command:
convert [input_file_path] -threshold 55% [output_file_path]
The threshold % can be varied to get the best result for your use case. Image below shows an example. It is important to note that for the image at hand, Binarization is not the best option as it loses some data.
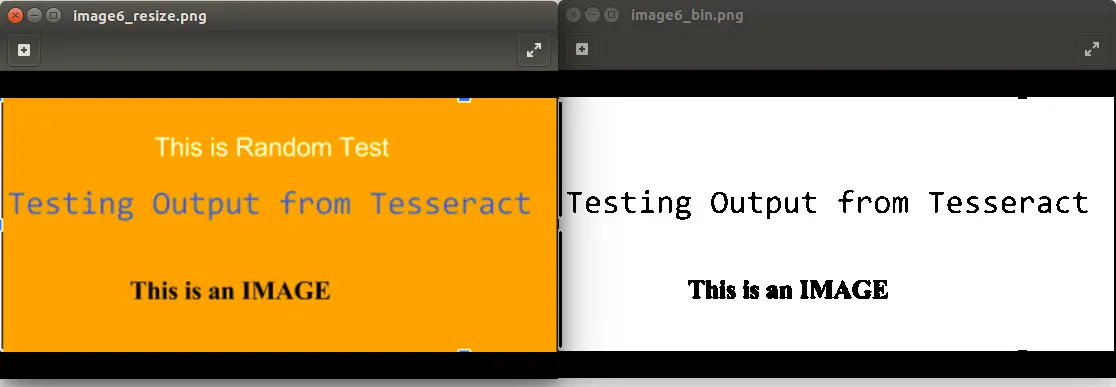
The following points must be kept in mind before applying any or all of the pre-processing techniques mentioned above:
- Depending on the use case, either or a combination of the preprocessing steps will be useful.
- when a pre-processing step leads to the decrease in accuracy, it should be ignored from the pre-processing steps.
- The percentages while resizing or thresholding varies from image to image, and thus a trial and error method needs to be applied to get the best possible percentage value to give the highest accuracy when Tesseract is run
Once you have completed the preprocessing, run Tesseract with the processed image to check the accuracy. Tesseract is very powerful but has some limitations when it comes to the type of image that is given as input. Hope you found this tutorial helpful.

