How to split a large archive file into multiple small files using Split command in Linux
On this page
Although one of the primary reasons behind creating archives is the ease of handling and transfer, sometimes the compressed file itself is so large that it becomes a nightmare to transfer it over network, especially when the network speed is slow.
So, what should be done in cases like these? Is there a solution to this problem? Well, yes - one solution is to split the compressed file into smaller bits, that can easily be transferred over network. At destination, you can join them back to get the original archive.
If the solution sounds interesting and you want to understand exactly how this can be done in Linux, you'll be glad to know that we'll be discussing all the important details step by step in this tutorial.
Before we proceed, please note that all the instructions and commands mentioned in this article have been tested on Ubuntu 14.04.
How to split large archives
There exists a command line utility - dubbed Split - that helps you split files into pieces. It's installed out of the box on most Linux distributions, so you don't have to perform any extra steps to download and install it. Following is the syntax of this command:
split [OPTION]... [INPUT [PREFIX]]
Here, INPUT represents the name of the file that needs to be split up into smaller bits, and PREFIX is the text that you want to be prefixed to the name of output files. OPTION, in our case, will be -b so that we can specify the size of the output files.
To understand Split's usage through an example, you need to first have a compressed file that you want to split. For example, I had the following 60MB .zip file in my case:

Here's the Split command in action:
![]()
So as you can see, using the -b option, I asked the Split command to break the large .zip file into equal pieces of 20MB each, providing the complete name of the compressed file as well as the prefix text.
Here's how I verified that the Split command actually did what it was asked to do:

As evident from the output in the screen-shot above, three files with names including the prefix I supplied and weighing 20MB each were produced in the output.
Of course, aside from .zip files, you can use the aforementioned method to split other types of compressed files as well. For example, here's how I used the same command we discussed before to split a .tar.xz file:
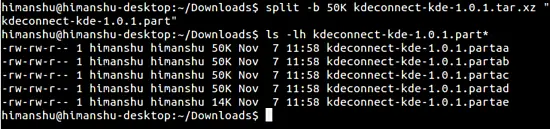
As you 'd have understood by now, if you want to split a file in multiple chunks that are to be sized in MBs, you need to use the letter M with the numeric figure that you provide on the command line. And if - like the case we just discussed - the files are to be sized in KBs, you should use the letter K.
So far, we've only used the -b option offered by the Split command; that's because it does what we want - tell the command to split the input file based on the size that follows this option on the command line. However, depending upon your case and requirement, you might want to use some of the other options the Split command provides.
Following is the list of options alongwith a brief explanation of what they do:
- -a, --suffix-length=N : generate suffixes of length N (default 2)
- --additional-suffix=SUFFIX : append an additional SUFFIX to file names.
- -b, --bytes=SIZE : put SIZE bytes per output file
- -C, --line-bytes=SIZE : put at most SIZE bytes of lines per output file
- -d, --numeric-suffixes[=FROM] : use numeric suffixes instead of alphabetic. FROM changes the start value (default 0).
- -e, --elide-empty-files : do not generate empty output files with '-n'
- --filter=COMMAND : write to shell COMMAND; file name is $FILE
- -l, --lines=NUMBER : put NUMBER lines per output file
- -n, --number=CHUNKS : generate CHUNKS output files.
- -u, --unbuffered : immediately copy input to output with '-n r/...'
Up until now, we have only discussed how to split a large archive into multiple smaller parts. Needless to say, that's of no use until you also know how to join them back to retrieve the original compressed file. So, here's how you can do that:
There's no special command line utility to join the smaller chunks, as the good old Cat command is capable of handling this task. For example, here's how I retrieved the Kaku-linux32.zip file through the Cat command:
![]()
You can extract the retrieved archive and compare it with the original one to cross verify that nothing has changed.
Conclusion
If you are a Linux user, and your daily work involves playing with large compressed files and sharing them with others over network, there are good chances that you might want to split an archive in some cases. Of course, the solution mentioned in this tutorial may not be the only one available, but it's for sure one of the simplest and least effort consuming.
In case you use a different approach to split large archives and then join them back, and want to share your solution with others, you can do so in comments below.

