How to clone disks with Linux dd command
In this tutorial, we'll refer to a practical example of the Linux dd command that can be used by system administrators to migrate or clone a Windows Operating System or a Linux OS from a larger HDD partitioned in MBR or GPT layout style to a smaller SSD. In this guide, we'll use as an example a Windows system installed on a hard disk with multiple partitions. This method can become quite complicated in case the HDD is partitioned in MBR scheme and contains an extended partition with multiple logical partitions or the partitions are out of order. I suggest you don't use this method if that's the case. In such cases, it's safer to use ddrescure which can clone your entire disk layout (partition table and used blocks inside each partition) without actually transferring the empty space. DDrescure can be obtained by installing gddrescue package from Ubuntu main repositories.
STEP ONE - Shrink Partition
You can resize a Linux or a Windows partition (shrink) to minimal size using a live Linux distribution such as Gparted or run gparted GUI utility from Ubuntu Desktop Live ISO image. Other paid Linux distributions you can use the manipulate disk partition file system sizes (ext2, ext4, NTFS, xfs) are Partition Wizard or Parted Magic . You can also use Microsoft Windows diskmgmt.msc utility in order to shrink an NTFS partition. By shrinking the free space of a partition, the required time that dd will take to copy non-used disk blocks, in case of huge partitions, will be drastically reduced. In case of a large partition with just a small percent of used space, it's advisable to shrink the file system because dd utility will also copy the unused space in the process (dd will also copy all free blocks of 100GB or 1 TB partition which has less than 10% of used space).
STEP TWO - Clone Disks
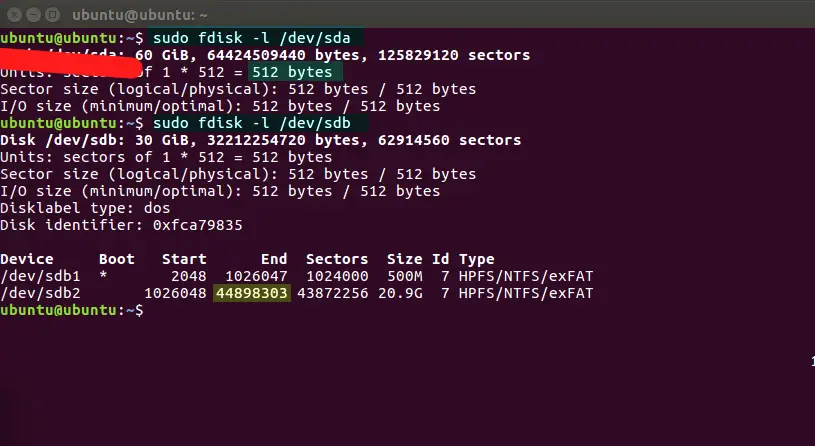
After the partition was resized to minimal, physically plug the second disk or SSD into the machine SATA/SCSI controller and boot-up the machine with a Live Linux distribution. Once the live Linux distribution has been loaded into RAM, open a Linux console and run fdisk -l /dev/sda (assuming that /dev/sda is your windows installation disk or C: drive in a windows environment) and note down the last "End" sector (44898303 as shown in the below example):
Example One - Clone MBR disk (Windows OS installed on the second partition)
In this test setup the disks are inversed, so /dev/sdb represents Windows installation the disk and /dev/sda represents the empty SSD.
Then run the following command with root privileges in order to clone Windows installation disk from HDD (/dev/sdb) to SSD (/dev/sda). pv utility is not installed by default in Ubuntu. You can install it by running:
sudo apt install pv
Then start the cloning process by issuing the below command:
sudo dd if=/dev/sdb bs=512 count=44898303 conv=sync,noerror | pv -s 21G |sudo dd of=/dev/sda
ATTENTION: the target disk must be at least the size of the total space occupied by all partitions up to the Windows partition from the source disk, including the Windows partition.
Explaining the commands used in the above example
dd - dd stands for "Copy and Convert". Some might say it stands for 'Data Destroyer' (in case you mislead the command some serious damage can happen) or Data Duplicate or Data Description. Use whatever description suits your needs!
if - the source disk (in/input file)
bs - Sector size value from fdisk output (Block Size or number of bytes to be read/write one time)
count - Last "End" sector from fdisk output incremented by one integer (+1) - How many 512 size blocks should copy before it stops. Here, it should transfer 44099584 sectors of 512 bytes in size.
conv=sync,noerror - sync I/O and don't stop in case you encounter block errors on the source disk
| - Linux pipe (interprocess communication channel in Linux or FIFO)
pv -s 21GB - monitor the cloning progress - Approximately 21GB should be transferred through the pipe
of - the target disk where the piped data is actually written (out/output file)
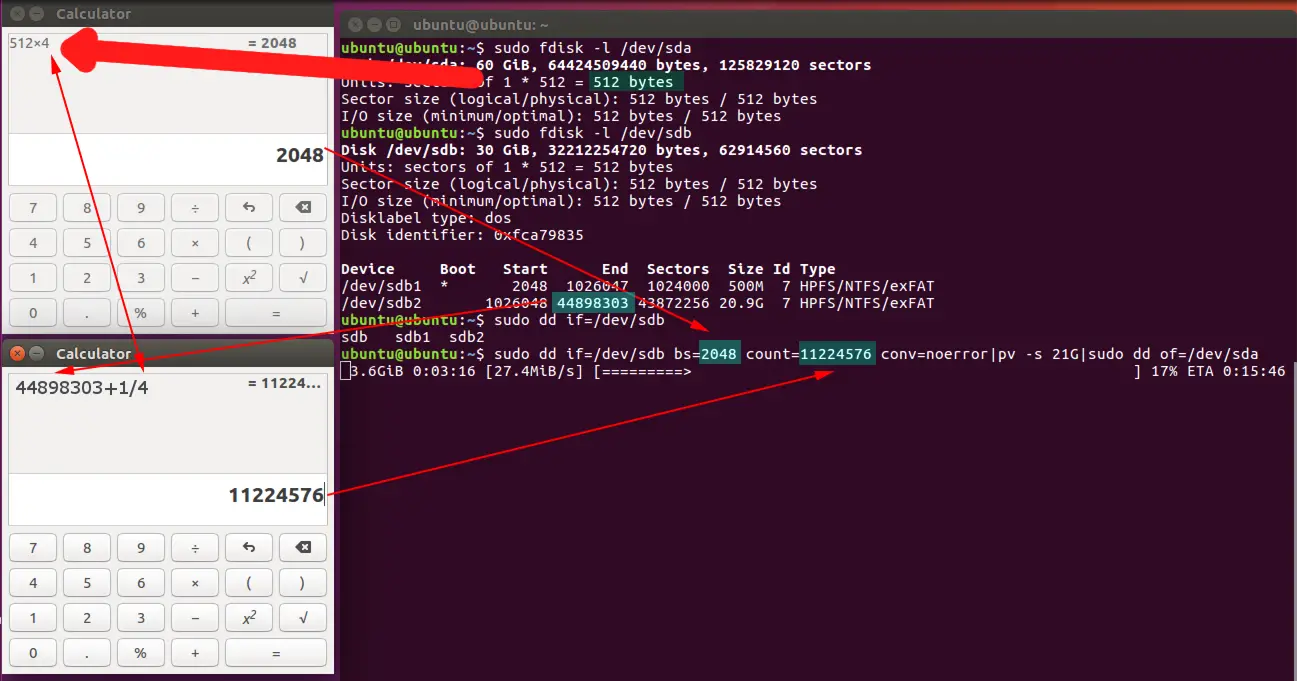
In case you want to operate with a larger Block Size than the standard disk block size (512), let's say up to four times the size of standard block size (2048), for speeding up things, you can do some simple math and multiply by four the standard block size of the disk (512x4) and then divide the total number of blocks +1 of the last partition by four.
Another Example
In this example the "End" of sda2: 44898303+1 divided by 4. dd will operate with a block size of 2048 bytes.
sudo dd if=/dev/sda bs=2048 count=44898303 conv=sync,noerror | pv -s 21G |sudo dd of=/dev/sdb
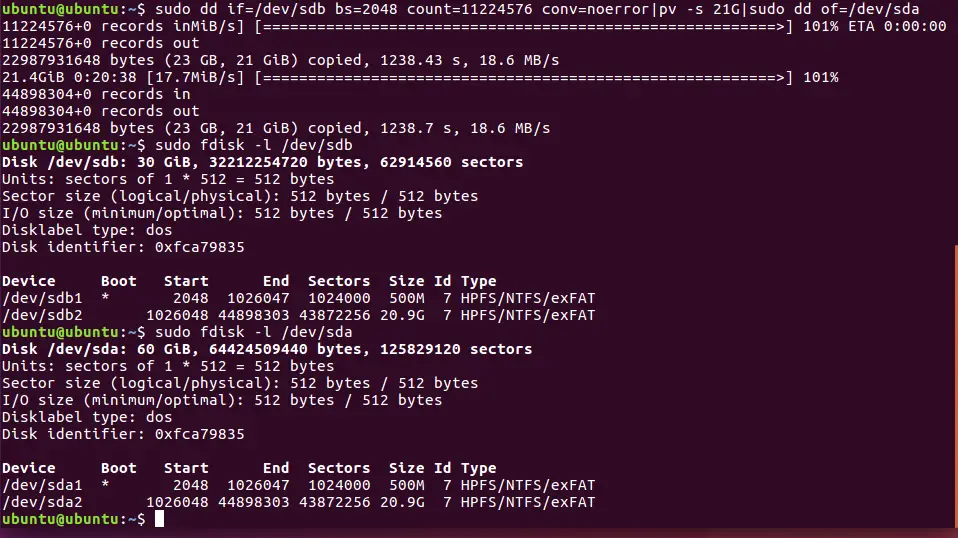
After the process finishes (depending on your disk size and speed it can take ten minutes or even hours) verify target disk using the same sfdisk command and compare the outputs from both disks. The results should be similar.
Example Two - Clone GPT disk (Windows OS installed on the fourth partition)
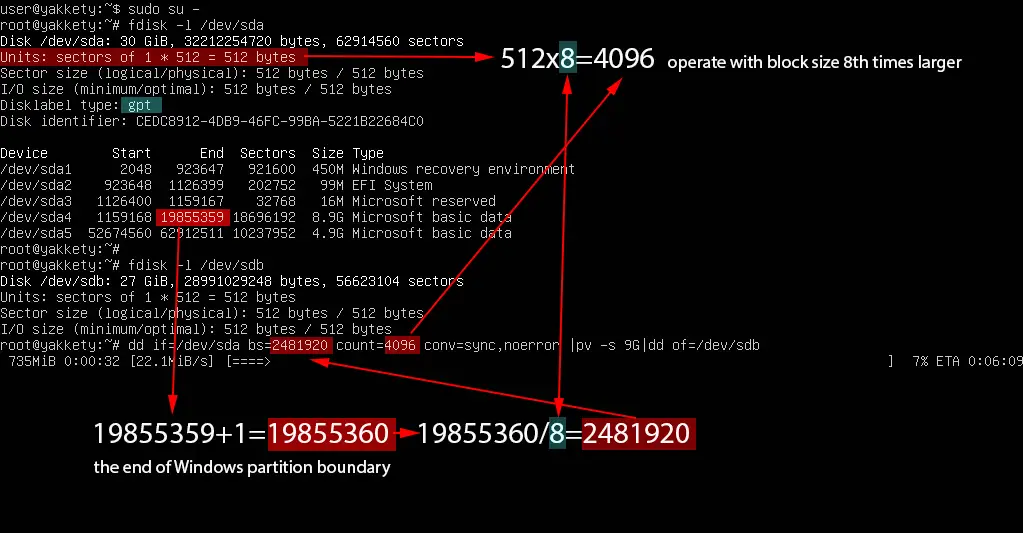
In this excerpt, dd will operate with a block size up to eight times the size of standard block size (4096) in order to transfer more blocks at once. The Windows OS resides in the fourth partition of the hard disk. All preceding Windows partitions must also be cloned. The disk will be fully copied until the last 19855359 sector, which represents the end of Windows partition boundary. Data that follows 19855359+1 sector represents D: partition in Windows, so this partition is of no interest to us since we'll only want to clone the operating system partition.
Multiply by eight the standard block size of the disk (512x8) and then divide the total number of blocks +1 of the last partition by eight as illustrated in the below image. The "End" of sda4 which represents the Windows partition is 19855359+1 divided by 8. dd operates with a block size of 4096 bytes.
sudo dd if=/dev/sda bs=4096 count=2481920 conv=sync,noerror | pv -s 9G |sudo dd of=/dev/sdb
In this example, because we're only copying Windows OS and not the entire disk data that follows the fourth partition we need to delete the last partition. We can delete it by running cgdisk command line utility directly from the console as illustrated on the following screenshots
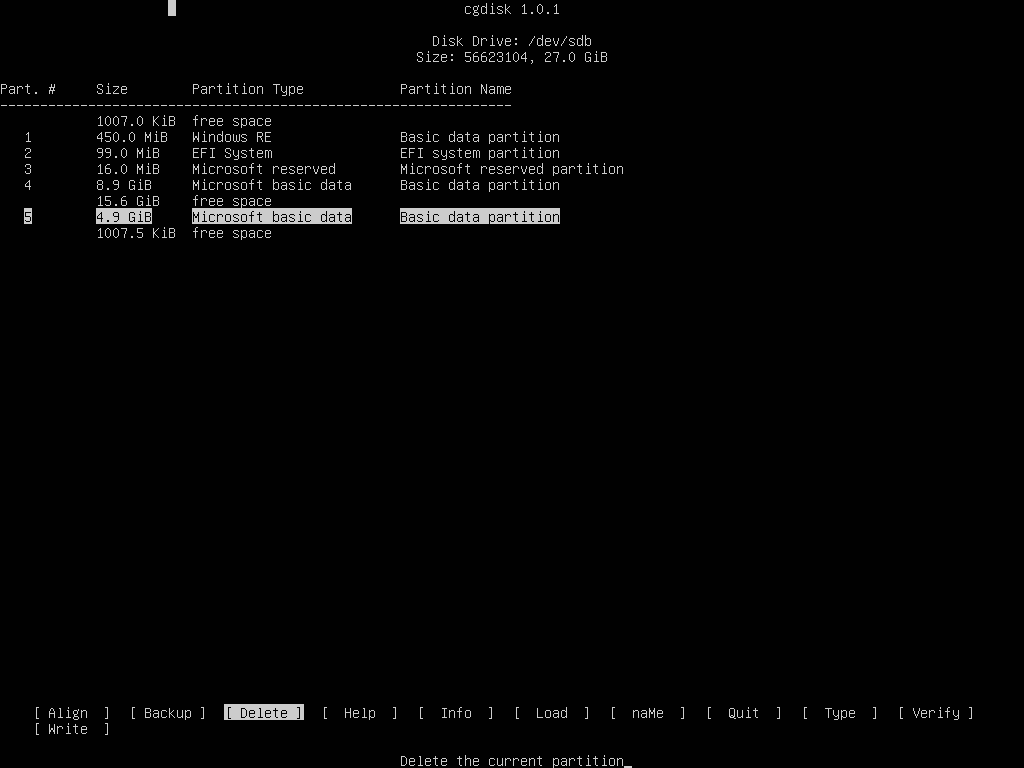
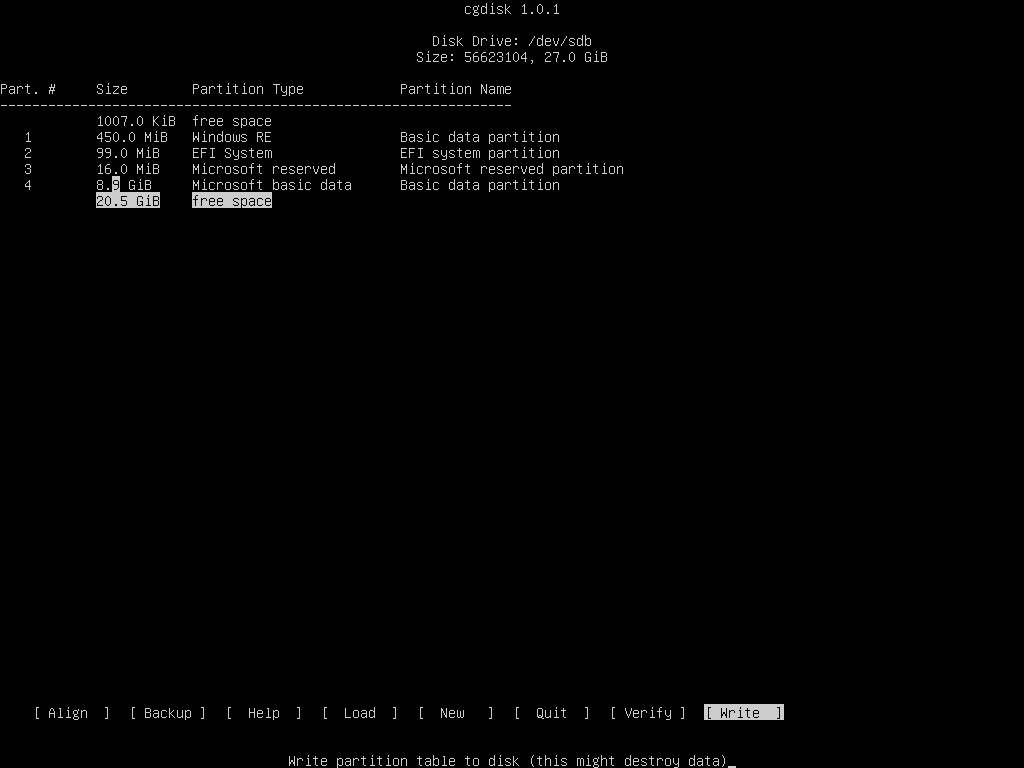
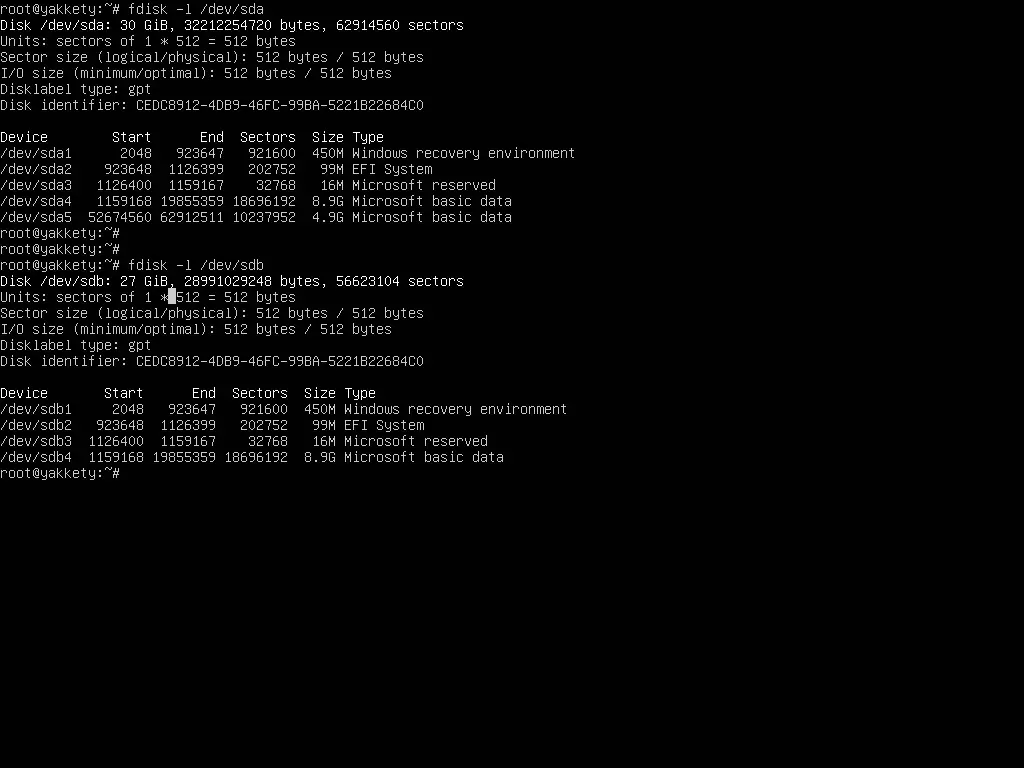
Verify the partition table differences on both disks by issuing fdisk command. The partition table should be similar, except 5th partition from /dev/sda which should be removed from the cloned disk (/dev/sdb ).
STEP THREE - Test the Cloned Disk
Finally, shut down the machine, unplug the old hard disk, and power on the computer with the newly cloned disk only. It should boot up in your operating system in no time. In case the machine refuses to boot, physically verify the SATA connectors on the motherboard and try to reverse them, or go to BIOS/UEFI settings and make sure the appropriate disk is enabled in the booting-up sequence.
Try not to boot up the machine with both disks plugged-in because it might confuse the bootloader, making your machine impossible to start the operating system. After you have the confirmation that your operating system boots up normally, use the same tool as for shrinking the file system to extend the cloned partition by adding the unallocated space.
Using this dd method you can transfer any variant of Windows or Linux OS with all your custom settings, installed programs, and files from a larger HDD to a smaller SSD, without the burden to install the OS from scratch and spend tons of hours to customizing it.

