How to Install Apache Kafka on Ubuntu 22.04
This tutorial exists for these OS versions
- Ubuntu 22.04 (Jammy Jellyfish)
- Ubuntu 18.04 (Bionic Beaver)
On this page
Apache Kafka is a distributed data store for processing streaming data in real-time. it's developed by Apache Software Foundation and written in Java and Scala. Apache Kafka is used to building real-time streaming data pipelines and applications that adapt to the data stream, especially for enterprise-grade applications and mission-critical applications. It's one of the most popular data stream platforms used by thousands of companies for high-performance data pipelines, streaming analytics, and data integration.
Apache Kafka combines messaging, storage, and stream processing in one place. Allow users to set up high-performance and powerful data stream for collecting, processing, and streaming data in real-time. It's used in modern distributed applications with the capability of scaling to handle billions of streamed events.
In this tutorial, you will install Apache Kafka on an ubuntu 22.04 server. You will learn how to install Apache Kafka manually from binary packages, which includes the basic configuration for Apache to run as a service and the basic operation using Apache Kafka.
Prerequisites
To complete this tutorial, you will need the following requirements:
- An Ubuntu 22.04 server with at least 2GB or 4GB of memory.
- A non-root user with root/administrator privileges.
Installing Java OpenJDK
Apache Kafka is a stream processing and message broker written in Scala and Java. To install Kafka, you will install the Java OpenJDK on your Ubuntu system At the time of this writing, the latest version of Kafka v3.2 required at least the Java OpenJDK v11, which is available by default on the Ubuntu repository.
To begin, run the apt command below to update the Ubuntu repository and refresh the package index.
sudo apt update
Install the Java OpenJDK 11 using the apt command below. Input Y to confirm the installation and press ENTER, and the installation will begin.
sudo apt install default-jdk
The Java OpenJDK is now installed on your Ubuntu system. Use the following java command to check and verify the java version. You will see the java OpenJDK v11 installed.
java version

Installing Apache Kafka
After installing Java OpenJDK, you will start the Apache Kafka installation manually using the binary package. At the time of this writing, the latest version of Apache Kafka is v3.2. To install it, you will create a new system user and download the Kafka binary package.
Run the following command to create a new system user named "kafka". This user will have the default home directory "/opt/kafka" and disabled the shell access.
sudo useradd -r -d /opt/kafka -s /usr/sbin/nologin kafka
Download the Apache Kafka binary package using the curl command below. You should get the Apache Kafka package "kafka_2.13-3.2.0.tgz".
sudo curl -fsSLo kafka.tgz https://dlcdn.apache.org/kafka/3.2.0/kafka_2.13-3.2.0.tgz
After the download is finished, extract the file "kafka_2.13-3.2.0.tgz" using the tar command. Then, move the extracted directory to "/opt/kafka".
tar -xzf kafka.tgz
sudo mv kafka_2.13-3.2.0 /opt/kafka
Now change the ownership of the Kafka installation directory "/opt/kafka" to the user "kafka".
sudo chown -R kafka:kafka /opt/kafka
Next, create run the following command to create a new directory "logs" for storing Apache kafka log files. Then, edit the Kafka configuration file "/opt/kafka/config/server.properties" using nano editor.
sudo -u kafka mkdir -p /opt/kafka/logs
sudo -u kafka nano /opt/kafka/config/server.properties
Change the default location for Apache Kafka logs to the directory "/opt/kafka/logs".
# logs configuration for Apache Kafka
log.dirs=/opt/kafka/logs
Save and close the file when you are finished.
Setting Up Apache Kafka as a Service
At this point, you have the basic configuration for Apache Kafka. Now how to run Apache Kafka on your system? The recommended way here is to run the Apache Kafka as a systemd service. This allows you to start, stop, and restart the Apache Kafka using a single command-line "systemctl".
To set up the Apache Kafka service, you need to set up the Zookeeper service first. The Apache Zookeeper here is used to centralize services and maintain controller election, configurations of topics, access control lists (ACL), and membership (for Kafka cluster).
The Zookeeper is included by default on Apache Kafka. You will set up the service file for Zookeeper, then create another service file for Kafka.
Run the following command to create a new systemd service file "/etc/systemd/system/zookeeper.service" for Zookeeper.
sudo nano /etc/systemd/system/zookeeper.service
Add the following configuration to the file.
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
When you are finished, save and close the file.
Next, create a new service file for Apache Kafka "/etc/systemd/system/kafka.service" using the below command.
sudo nano /etc/systemd/system/kafka.service
Add the following configuration to the file. This Kafka service will be run only if the Zookeeper service is running.
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties > /opt/kafka/logs/start-kafka.log 2>&1'
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
Save and close the file when you are finished.
Now reload the systemd manager using the below command. This command will apply the new systemd services that you just created.
sudo systemctl daemon-reload
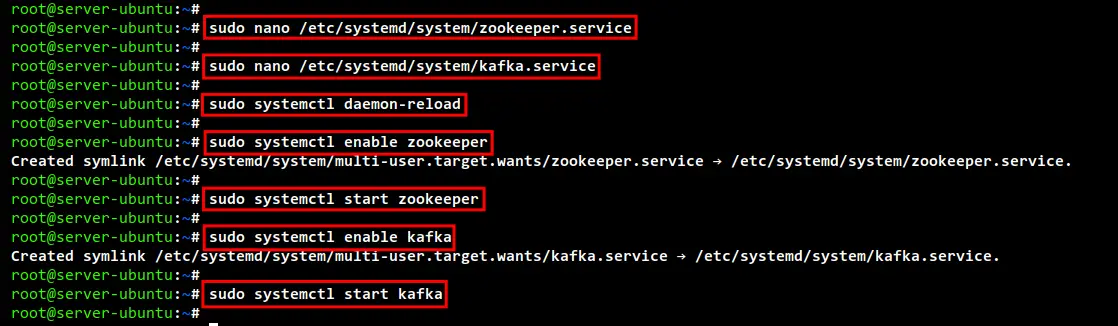
Now start and enable the Zookeeper service using the below command.
sudo systemctl enable zookeeper
sudo systemctl start zookeeper
Then, start and enable the Apache Kafka service using the following command.
sudo systemctl enable kafka
sudo systemctl start kafka
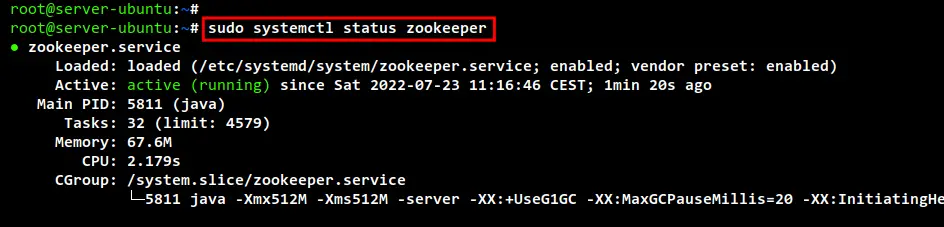
Lastly, check and verify the Zookeeper and Apache Kafka services using the command below.
sudo systemctl status zookeeper
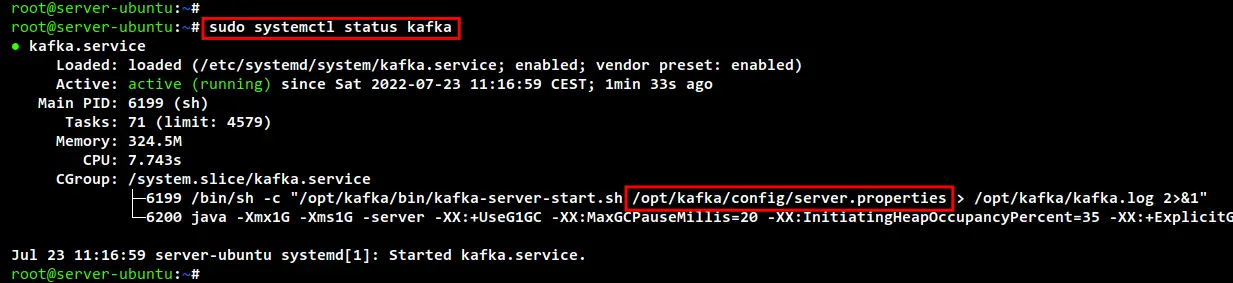
sudo systemctl status kafka
In the following output, you can see the Zookeeper service is enabled and will be run automatically at system startup. And the current status of the Zookeeper service is running.
The Apache Kafka service, it's also enabled and will be run automatically at system startup. And it's now "running".
Basic Apache Kafka Operation
You have finished the basic Apache Kafka installation, and it's running. Now you will learn the basic operation of Apache Kafka from the command line.
All Apache Kafka command-line tools are available in the "/opt/kafka/bin" directory.
To create a new Kafka topic, use the script "kafka-topics.sh" as below. In this example, we are creating a new Kafka topic with the name "TestTopic" with 1 replication and partition. And you should get the output such as "Created topic TestTopic".
sudo -u kafka /opt/kafka/bin/kafka-topics.sh \
--create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic TestTopic
To verify the lists of available topics on your Kafka server, run the following command. And you should see the "TestTopic" that you just created is available on the Kafka server.
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092

You have created the Kafka topic, now you can try to write and streams data on the Apache Kafka using the standard command-line "kafka-console-producer.sh" and "kafka-console-consumer.sh".
The script "kafka-console-producer.sh" is a command-line utility that can be used to write data on Kafka topic. And the script "kafka-console-consumer.sh" is used to stream data from the terminal.
On the current shell session, run the following command to start the Kafka Console Producer. Also, you will need to specify the Kafka topic for that, in this example, we will use the "TestTopic".
sudo -u kafka /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TestTopic
Next, open up another shell or terminal, and connect to the Apache Kafka server. Then, run the following command to start the Apache Kafka Consumer. Be sure to specify the Kafka topic here.
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TestTopic --from-beginning
Now you can type any messages from the Kafka Console Producer and the messages will automatically appear and streamed on the Kafka Console Consumer.
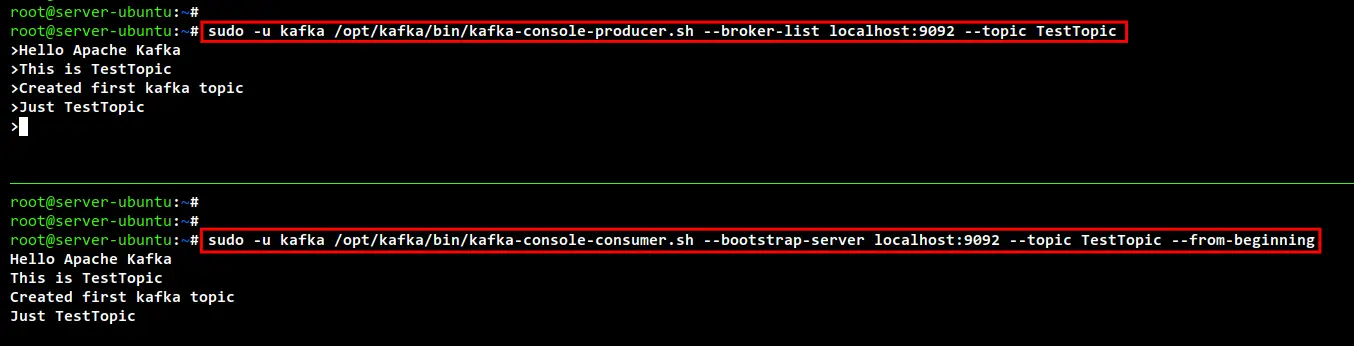
Now you can just press "Ctrl+c" to exit from the Kafka Console producer and Consumer.
Another basic Kafka operation that you should know here is how to delete a topic on Kafka. And this can be done also by using the "kafka-topics.sh" command-line utility.
If you want to delete the topic "TestTopic", you can use the following command. Now the "TestTopic" will be removed from your Kafka server.
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic TestTopic
Import/Export Your Data as Stream using Kafka Connect Plugin
You have to learn the basic operation of Apache Kafka by creating topics, and streaming messages using the Kafka Console Producer and Consumer. Now you will learn how to stream messages from a file via the "Kafka Connect" plugin. This plugin is available on the default Kafka installation, default plugins for Kafka are available on the directory "/opt/kafka/libs" directory.
Edit the configuration file "/opt/kafka/config/connect-standalone.properties" using nano editor.
sudo -u kafka nano /opt/kafka/config/connect-standalone.properties
Add the following configuration to the file. This will enable the Kafka Connect plugin that is available on the "/opt/kafka/libs" directory.
plugin.path=libs/connect-file-3.2.0.jar
When you are finished, save and close the file.
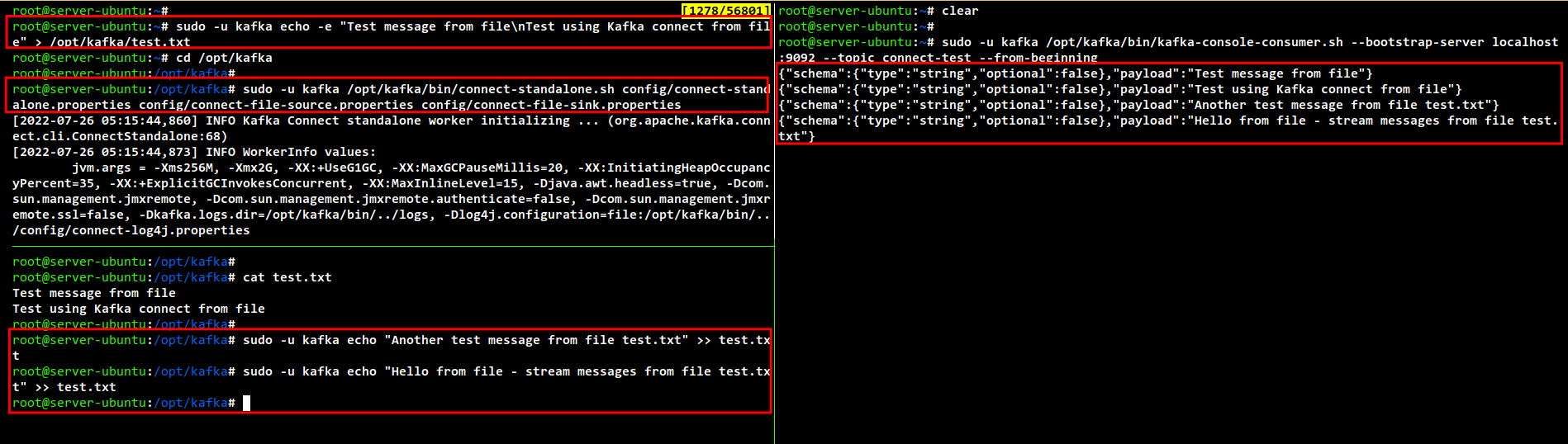
Next, create a new example file that you will import and stream to Kafka. Based on the Apache Kafka configuration files, you must create the file "test.txt" under the Kafka installation directory "/opt/kafka".
Run the below command to create a new file "/opt/kafka/test.txt".
sudo -u kafka echo -e "Test message from file\nTest using Kafka connect from file" > /opt/kafka/test.txt
From the "/opt/kafka" working directory, run the following command to start the kafka connector in standalone mode.
Also, we add an additional three configuration files as parameters here. All of these files contain the basic configuration on which the data will be stored, on which topic, and which file will be processed. The default value of these configurations is the data will be available on the topic "connect-test" with the source file "test.txt" that you just created.
You will see a lot of the output messages from Kafka.
cd /opt/kafka
sudo -u kafka /opt/kafka/bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
Now open another terminal shell/session and run the following command to start the Kafka Console Consumer. In this example, the data streams will be available on the topic "connect-test".
Now you will see the data on the file "test.txt" is streamed on your current Console Consumer shell.
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
If you try to add another message to the file "test.txt", you will see the message will automatically be streamed on the Kafka Console Consumer.
sudo -u kafka echo "Another test message from file test.txt" >> test.txt
Conclusion
In this tutorial, you have learned how to install Apache Kafka for stream processing and message broker on the Ubuntu 22.04 system. You have also learned the basic configuration of Kafka on the Ubuntu system. Additionally, you have also learned the basic operation using Apache Kafka Producer and Consumer. And at the end, you have also learned how to stream messages or events from a file to Apache Kafka.

