Installing NLTK and using it for Human language processing
NLTK stands for "Natural Language Tool Kit". It is a python programming module which is used to clean and process human language data. Its rich inbuilt tools helps us to easily build applications in the field of Natural Language Processing (a.k.a NLP).
A corpora is a set of words present in a particular language and NLTK provides over 50 different corpora to work on and provides core libraries like POS tagging, End of speech tagging, tokenization, semantic reasoning, classification, etc. Following is a brief description of the 5 main features or steps used in NLP, that can be easily performed using NLTK:
- End Of Speech Tagging ( EOS tagging): This involves , braking down a text into a collection of meaningful sentences.
- Tokenization: splitting sentences into words. It not only works on white spaces , but also removes the stopwords like (.,?,!,etc) and it is a set, which means duplicate words are removed.
- Part of Speech Tagging (POS tagging): Tag words to indicate the type of word it is. The tags are coded. for nouns, verbs of past tense,etc, so each word gets a tag.
- Chunking: The process of grouping word with similar tags. The result of chunking would a tree like structure.
- Extraction: Once the data is chunked, we can extract only the nouns , or only the verbs , etc to meet the needs.
Now, this may seem very cool but is this the best module that could be used? Well, the answer to that depends on the task at hand. In general NLTK is slow, but very accurate. There are other modules like PsyKit which is faster but comes with a trade-off on accuracy.So, For applications when accuracy precedes time, NLTK is the right choice. This post shows how NLTK can be installed and used with an example.
2 Download and Install NLTK
NLTK can be installed very easily using the "pip" installer. Before we install NLTK, we have to install numpy as well.Use the following commands:
sudo pip install -U numpy
sudo pip install -U nltk
The image below shows the execution of nltk. Please note that installing numpy is similar but might take more time to install depending on the processor of your system.
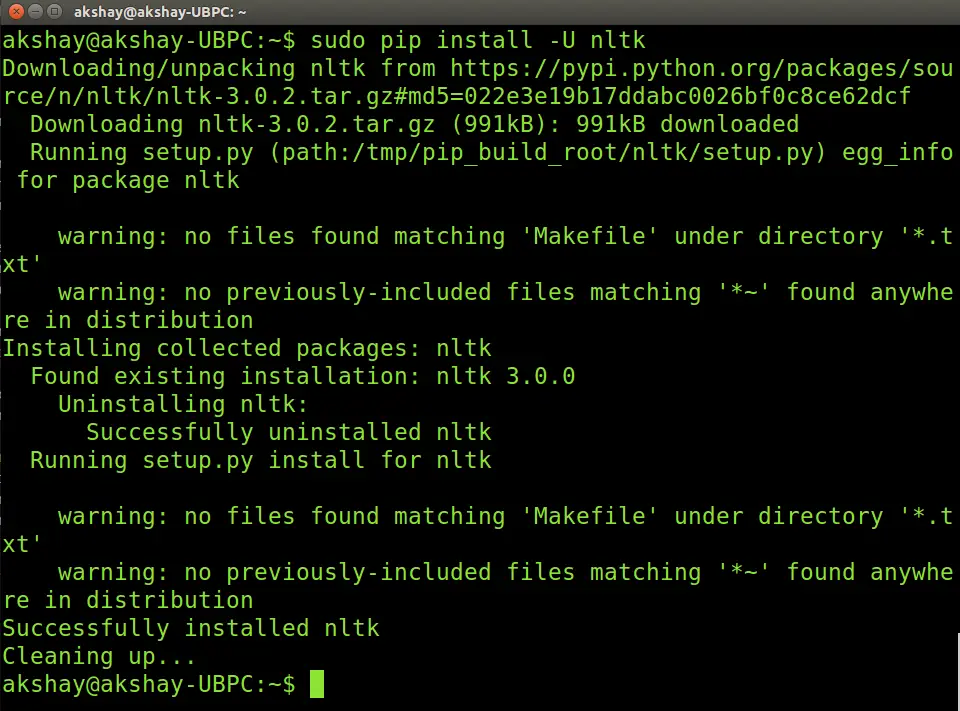
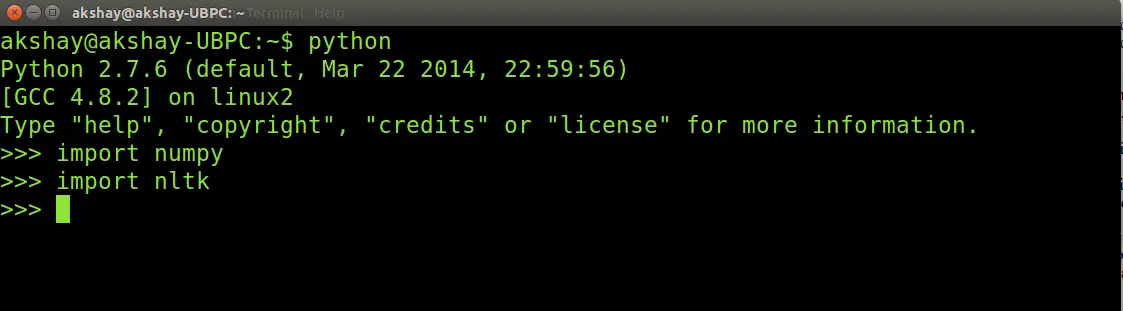
Once done, you can test if it has installed correctly by using the 2 commands in the following picture and making sure it runs without an error.
3 Installing NLTK data
Once that you have confirmed that nltk is installed, we will have to download and install NLTK data. Nltk Data consists of the corpora and all the words in a language along with various grammar syntaxes, toy grammars, trained models, etc. They help the users to easily process languages by applying the various functions. Please note that installing nltk data is a long process it involves downloading over 1 GB of data. To download the nltk data, in a terminal type "python" to open python interpreter and type the following two commands:
>>> import nltk >>> nltk.download()
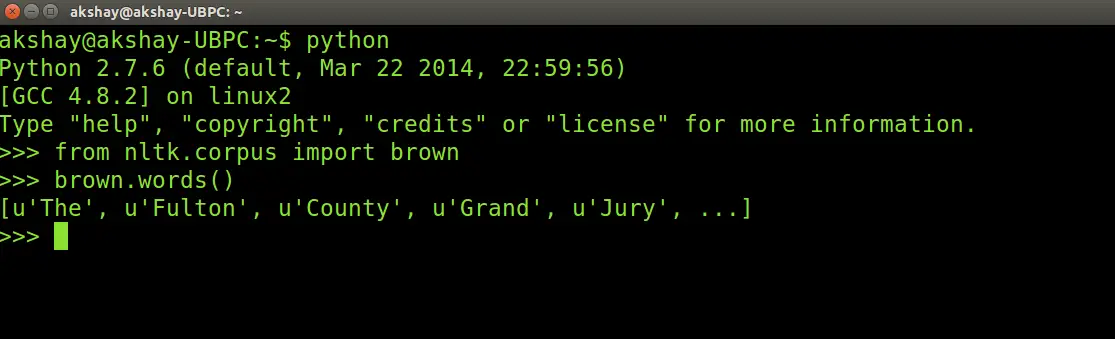
A new window should open, showing the nltk downloader. install it in the "usr/share/nltk_data" folder. Once done test if it has been downloaded by typing the commands and getting the output as shown in the image below.
4 Examples of using NLTK
Now we can try out some examples of NLP tasks performed using NLTK. The 5 processes of EOS detection, Tokenization, POS tagging , Chunking and extraction is demonstrated here:
4.1 EOS Detection
The end of speech tagging breaks a text into a collection of meaningful sentences. We do this because the further steps work on individual sentences. Below is an example and output of EOS detection.
>>> import nltk >>> text = "Mrs. Hudson made a cup of tea. She is a wonderful woman." >>> sentences = nltk.tokenize.sent_tokenize(text) >>> sentences ['Mrs. Hudson made a cup of tea.', 'She is a wonderful woman.'] >>>
The use of nltk's corpus can be seen above. It knows that "Mrs." is not a sentence but an abbreviation. Thus it is included as a part of a sentence and not a sentence by itself.
4.2 Tokenization
This step operates on individual sentences, splitting them into tokens. so we get a list of lists that contain tokens. Example below is the continuation of the previous step.
>>> tokens = [nltk.tokenize.word_tokenize(s) for s in sentences] >>> tokens [['Mrs.', 'Hudson', 'made', 'a', 'cup', 'of', 'tea', '.'], ['She', 'is', 'a', 'wonderful', 'woman', '.']] >>>
Here we can see that tokens are not only made up of words but also end of sentences. It is important to note that the Tokenization does not only split sentences into words, it also has the capability to break sentences into tokens where whitespace in not a character to separate words.
4.3 POS tagging
POS means pat-of-speech and in this step a POS information is assigned to each of the token in the tokens list. Each of this POS information represent what kind of speech it is. For example, a tag 'VBD' indicates a verb that’s in simple past tense, and 'JJ' indicates an adjective. This step helps us to arrange or order the words in the next step. An example is given below.
>>> PosTokens = [nltk.pos_tag(e) for e in tokens]
>>> PosTokens
[[('Mrs.', 'NNP'), ('Hudson', 'NNP'), ('made', 'VBD'), ('a', 'DT'), ('cup', 'NN'), ('of', 'IN'), ('tea', 'NN'),
('.', '.')], [('She', 'PRP'), ('is', 'VBZ'), ('a', 'DT'), ('wonderful', 'JJ'), ('woman', 'NN'), ('.', '.')]]
>>>
4.4 Chunking and Extraction
Chunking refers to the process of assembling complex tokens based on tags. Nltk also allows a custom grammar to be defined for chunking. Extraction on the other hand refers to the process of going through the existing chunks and tagging them as named entities, such as people, organizations, locations, etc. an example :
>>> chunks = nltk.ne_chunk_sents(PosTokens) >>> for each in chunks: ... print each ... (S Mrs./NNP (PERSON Hudson/NNP) made/VBD a/DT cup/NN of/IN tea/NN ./.) (S She/PRP is/VBZ a/DT wonderful/JJ woman/NN ./.) >>>
We can see above that Mrs. Hudson has been recognised as a person. All this information is stored in the form of a tree.
5 Conclusion
From the sample given above, we can see how easily we are able to process data. Once these 5 steps have been applied, we can go ahead and apply various algorithms to process/rank the data and extract useful information from it. One example where this can be used is "Automatic text summarization". To conclude, Nltk is a powerful, accurate yet a bit slower tool compared to others. It can be used for applications which have accuracy as a priority.
6 Official Link
For detailed usage information on the hundreds of tasks and functions of nltk along wth usage, visit their official website: http://www.nltk.org/genindex.html

