Redundant Array Of Inexpensive Disks (RAID) - Technical Paper - Page 2
3.3. RAID LEVEL 3:
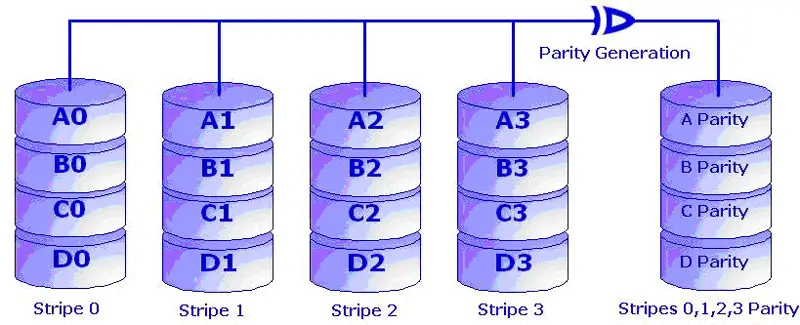
Fig: Striping with Bit Level Parity
RAID 3 implements byte level striping with parity. It requires a minimum of 3 disks to be implemented. Data to be written is divided into stripes and stripe parity is calculated for every write operation. The stripe parity is stored on a separate parity disk. Provides fault tolerance and disk usage is better than that of mirroring. Controller design is quite complex. Write operations are slow as there are overheads of parity calculation and writing parity to a separate disk. Read operations are faster as compared to write.
3.4. RAID LEVEL 4:
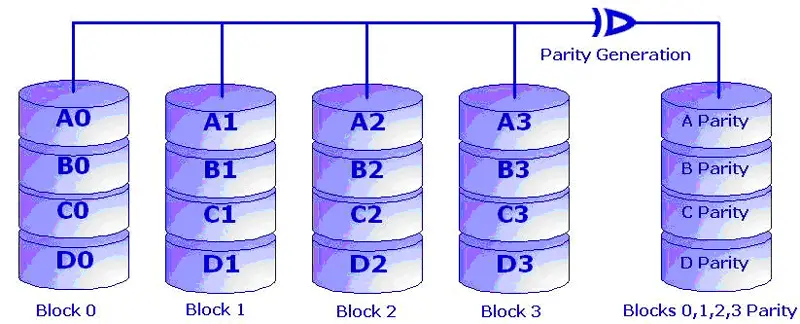
Fig: Striping with Block Level Parity
RAID 4 implements block level striping with parity. It requires a minimum of 3 disks to be implemented. Each entire block is written onto a data disk. Parity calculation for same rank blocks is generated during write operation and recorded on the separate parity disk. If one of the data drives in array fails, the parity information can be used to reconstruct all data. However if more than one disks fail, whole of the data is lost. RAID 4 can sustain only one disk failure at a time. The Controller design is quite complex. Read operations are same as that if single disk system but sequential writes are slow and random write operations are slower. Since the parity information has to be calculated every time and updated during writes, the parity disk becomes a bottleneck. It is difficult to rebuild data in case of a disk failure.
3.5. RAID LEVEL 5:
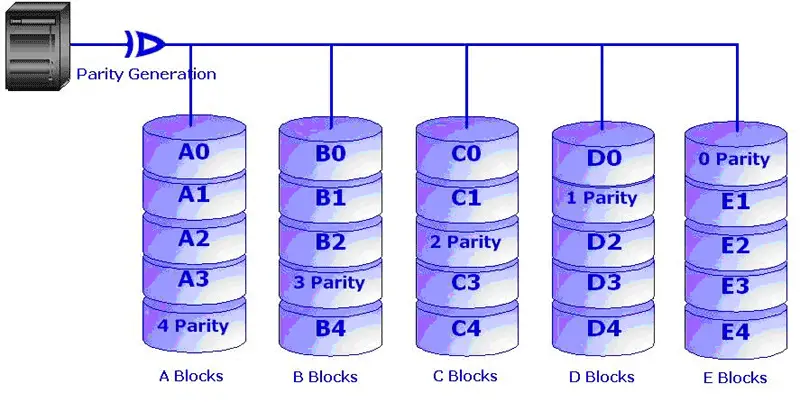
Fig: Distributed Parity
RAID 5 is the most useful RAID mode when a larger number of physical disks are combined, and redundant information in terms of parity is still maintained. To implement RAID-5 a minimum of 3 disks are required. The difference between RAID-5 and RAID-4 is that the parity information is distributed evenly in the drives, thus avoiding the bottleneck problem in RAID-4. RAID-5 also can sustain maximum one disk failure at a time. Reading is similar to RAID 0 but writes can be expensive. Writing to disk array requires reading of whole row, calculating parity and then rewriting data which makes the writing a bit slow. The drawbacks of RAID-5 are that the controller design is very complex and rebuilding data in case of disk failure is difficult if compared to RAID level 1.
3.6. RAID LEVEL 6:
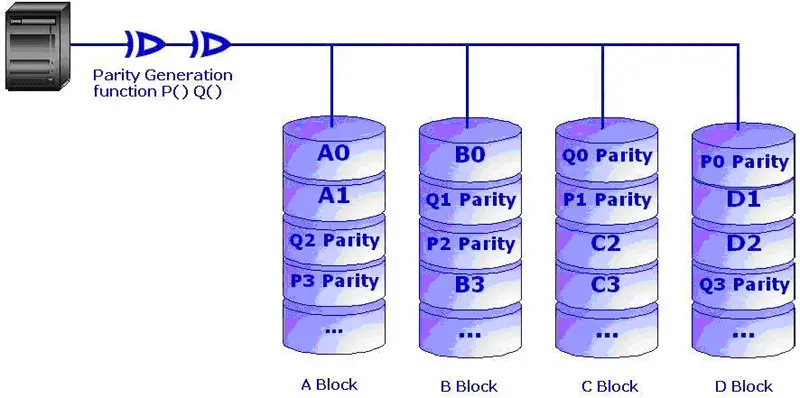
Fig: Distributed Dual Parity
RAID-6 is an extension of RAID-5 to provide additional fault tolerance by using dual distributed parity schemes. Dual parity scheme helps survive two disk failures at a time without data loss. Two parities are calculated through two independent parity schemes or functions and distributed evenly through the participating drives. It is a perfect solution for mission critical applications. Read performances are same as that in RAID-5 but writes are slow due to dual parity calculation overhead. Disk usage is less as compared to RAID-5 as more space is required to store two parities.
3.7 Other RAID Levels:
In order to improve performance multiple RAID level can be combined, for example RAID-10 is implemented by combining RAID-1 and RAID-0. Similarly RAID-50 can be implemented using RAID-5 and RAID-0.
4. RAID Limitations
In spite of large array of features that RAID provides, it has some limitations too. There is always a limit to the fault tolerance that RAID system can provide. RAID 0-5 can afford 1 disk failure at a time where as RAID 6 can sustain up to 2. Using multiple RAID levels can increase this to say 3 disks or more, but there is still a limit to it. Simply implementation of RAID doesn't guarantee total data security. There are chances that even the RAID controller fails. Some times an extra RAID controller is also employed, so that system continues to work in case of controller failure (called duplexing). This increase the hardware cost involved in setting up RAID.
Using RAID usually slows down the write operations on disks due to writing of redundant information.
If RAID 0 is employed which doesn't provide fault tolerance as there's no redundancy involved in it, the risk of data loss is always there. In case of disk failure (RAID 0), one can recover data only from the regular backups that were taken in the tapes.
5. Read and Write Performance
Now when we are clear with the key concepts in a RAID system we can analyze their Read and Write performances. The data is stored in disk arrays in different ways. If there is redundancy in data, which means it has to be written in more than one place or if parity is being calculated then data has to be written along with the parity in specific way. However when one has to read the data, he might not be interested in reading the redundant data at all. The read and write operations differ in every implementation. We discuss every solution one by one:
5.1 Mirroring:
The write operation in case of mirroring is bit slower than the read operation. The reason being every bit of data needs to be written twice in two disks, which makes the write operation a bit slow. In case of reading - the data can be read from a single disk without looking into the disk with duplicate information. The other drive can be utilizes to fulfill another read request. This makes read operation in RAID 1 better than reading from a single disk system.
5.2 Striping without parity:
This technique is employed in RAID level 0. It has same read and write performance as it requires reading the striped data in the same way as it was written i.e. if the stripes were written in 3 disks, they'll be read from three disks. Same numbers of drives are accessed both in read and write.
5.3 Striping with Parity:
The read operation is faster than write operation in this case as there's no need to read the redundant information i.e. parity. The sequential writes are far slow than striping without parity as parity calculation needs to be done for each write as well as extra parity values also have to be written along with the data in the additional disk. Random writes in case striping with parity are slower than the random write operation in striping without parity. The reason being, every time a block of data in a stripe is changed, the parity needs to be recalculated. For this first the whole data needs to be read, and then write the changed parity along with the data.
5.4 Stripe size and width:
Stripe width refers to the number of stripes that can be written to the disk or read from it simultaneously which is equal to the number of disks in the array.
Thus an array having 3 disks will have a stripe width of three.
Read and write performances in a striped array increases with the increase in stripe width. The reason being, if we add more disks to the array, this would increase parallelism and more drives can be accessed simultaneously.
Stripe size refers to size of stripes that is written to the disk. The stripes can be at bit level as in RAID-3 or at block level as in RAID-0, 4, 5, 6. If the stripe size is decreased, the file will be written across many drives. Say if we have a drive array of 5 disks. A file of 300 KB will be written to 3 drives if the stripe size is 100 KB. If the stripe size is increased to 150 KB, the file will be written in only 2 drives. Thus we see that more the number of drives, more would be parallelism and more will be the data transfer rate.
6. Potential benefits of using RAID
6.1 Fault Tolerance/Reliability:
RAID system provides redundancy, which means some data is duplicated such that if there is a disk failure, the original data can be recovered using the redundant data. Thus we can say a RAID storage system provides increased reliability than a single disk as there are less chances of whole system going down at a point of time than a single disk failure. However the term "reliability" is always relative to what we are comparing with.
Reliability of a device or system can be defined as the possibility of the device to remain working in case of some failure, which is measured over some period of time. More the components used in a system, lesser is its reliability as compared to the system having lesser individual components. As the reliability of system as a whole, depends upon the weakest link (component) in the system.
One question that arises here is, if the overall reliability goes down, why we want to setup such a system at all. But the answer is we are more focused on the reliability of system to protect our data. This means even though the RAID system is operating in degraded mode - with one or multiple disk failure, our data doesn't get affected at all. One can always replace the failed disk with a new one and recover data easily from it.
Capability of the RAID system to with stand disk failure and protect data depends on the implementation i.e. RAID levels. RAID Level 0 has no redundancy so it doesn't provide any fault tolerance. Other RAID levels - 1, 2, 3, 4, 5, 6 etc provide some degree of tolerance i.e. they can survive one disk failure, while RAID 6 can sustain 2 hard disk failures at a time. Other implementations include using multiple RAIDs in one e.g. RAID-10.
6.2 High Availability:
RAID provides high availability of data. Even in case of disk failures one has the access to data without disruption. Some RAID systems provide hot drive spare and disk swapping features as well to improve availability.
6.3 Increased Storage capacity:
If we are using RAID, capacities of all the disks in the array are combined and presented to the user as a single disk with a large capacity. This can have major advantages, for example - if some user has a large database which requires big disk space of 1000GB. Normally we don't get disks of this capacity in market. Only solution for user here is to use smaller capacity disks that are available in market. If he decides to use 7 disks of 160 GB capacity, he will have to split up his database into 7 parts to store all of his data. Using RAID can simplify this problem. Whereas he opts to create a RAID device, he'll have a single disk, 1120GB in capacity. Now he doesn't need to split up the database into multiple parts.
6.4 Performance:
RAID system improves data access from hard disks which are limited due to mechanical issues like rotation of the spindle and moving of the actuator arms. Using a RAID controller which is designed for these kinds of works helps improved reading and writing from the disks. Since there is a limit to the speed at which the disk spindle can rotate, there's also a limit to the speed at which data can be read from the disk. Using one or more RAID controllers can allow simultaneous reads from array of disks, thus improving read performance. However the read/write performances differ in various RAID levels and other factors like stripe size, usage of parity etc. are also involved.
Note: Refer following link for comparison between various RAID levels http://www.storagereview.com/guide2000/ref/hdd/perf/raid/levels/comp.html
7 Implementing Software RAID in Linux
Linux operating systems provides drivers for RAID, which can be used to implement software RAID. Currently Linux provides drivers for RAID levels 0, 1, 4 and 5.
Software RAID devices are also block devices, just like ordinary disks or even disk partitions. They can work on most block devices like IDE or SCSI devices. A RAID device can be created from a number of other block devices - for example, a RAID-0 or RAID-1 can be built from two ordinary disks, or from two disk partitions.
Steps to create RAID-1:
Here's an example which shows how to create RAID-1 using the Linux tool "mdadm".
Create two partitions, one on each disks /dev/hda and /dev/hdb of any size, say 100 MB each.
# fdisk /dev/hda
Enter command (m for help): n <n is used to create a new partition>
Enter starting cylinder 770 to 1300(770 default): 770
Enter partition size: +100M
Partition /dev/hda8 created
<Now the partition has been created as Linux partition with hexadecimal code "83", however we need to change it to RAID, the code for which is "fd". Enter "l" on the command prompt to view all the codes>
Enter command: l
<To toggle hexadecimal code, enter command "t">
Enter command: t
Enter partition number (1-8): 8 <we need to create RAID using this partition>
Enter Hexadecimal code: fd
<Now save all changes and quit the fdisk menu >
Enter command: w
# partprobe
<program that informs the operating system kernel of partition table changes, by requesting that the operating system re-read the partition table.>
<Similarly create another partition of same size on the other disk, say its /dev/hdb9>
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/hda8 /dev/hdb9
The above command creates a RAID-1 device /dev/md0.
--level for which RAID level one want s to create
--raid-devices for number of participating partitions or devices in RAID
Once RAID device is created, it is ready to be formatted.
# mkfs.ext3 /dev/md0
<This command formats device in ext3 filesystem>
# mdadm -details /dev/md0
<command to see if device is up and working>
<We can mount this device on any directory say /raid/ directory.>
# mkdir /raid
# mount /dev/md0 /raid
An entry for this device has to be done in the /etc/fstab file so that the partitions are not lost upon system reboot.

