Redundant Array Of Inexpensive Disks (RAID) - Technical Paper
Arvind Kumar
May 2008
Version 1.0
1. Introduction
1.1 Background:
The storage capacity and data retrieval speeds of Hard Disks have increased multiple folds in last few years. However for large business organizations, which not only need to store terabytes of invaluable data but access them frequently as well. These organizations cannot afford to let their systems go offline even for a short duration of time. Moreover they cannot even think of loosing even small amount of data due to disk failure or for that matter any other reason.
1.2 Issues:
A single hard disk cannot fulfill all these requirements no matter how large is the storage capacity or how good the performance and quality of disk is. The need here arises of a system that can store large volumes of data, provides fault tolerance, scalable in terms of increasing storage capacity and above all that can be reliable.
1.3 Solution:
RAID - Redundant Array of Inexpensive Disks, system solves most of the above stated problems. The idea behind RAID is usage of multiple independent hard disks, such that they appear to be a single large disk to the user of system, but at the same time provide faster access and data protection. RAID can be implemented in a number of ways depending on the type of application and environment where they are intended to be used. However every innovation that eases our problems comes with an added cost and complexity. But as stated, no one wants to loose their data which is invaluable as compared to the cost spend for implementing RAID.
1.4 Types of RAID:
RAID can be implemented as Hardware or Software. A hardware RAID system requires a dedicated RAID Controller, on the other hand a software RAID doesn't require any additional hardware and is bundled as a feature in the operating system. Since hardware RAID employs dedicated controller setup for its implementation, it has performance benefits over the software RAID.
Due to decreasing costs of the hardware, sooner or later the RAID subsystem would be a part of basic PC system configuration.
1.5 RAID - How useful it is?
We saw that RAID offers a lot of advantages over usage of a single disk system. However it is not a magic wand that can blow off all the issues and problems. If we simply say that some RAID level will always provide fault tolerance with high availability and improved performance we MIGHT be wrong. It all depends upon the specific usage, which RAID level we intend to use and how do we implement and manage it. We'll discuss these issues in detail.
2. RAID Level Implementations and concepts
Different RAID levels are implemented differently and have different behaviors. Depending on the implementations the performance of each RAID level is different. One has to understand the key concept of how the disks are arranged in an array, how fault tolerance is to be provided - i.e. using mirroring or parity. Read and Write operations can be affected in few cases. Not to forget there's cost and complexity issues involved as well.
Following are the terms one should understand before using the RAID system:
2.1 Drive Array:
A drive array is a collection of hard drives that are managed in a special way. All the drives are formatted in same file system and most implementations (RAID levels) want the drive size to be same.
2.2 Physical Drives:
A physical drive is actually a basic hard disk which is a component of RAID system. Multiple physical drives are used to form a drive array.
2.3 Logical Drives:
Logical drives are created out of physical drives which gives RAID user an illusion that he has a single (or multiple) hard drives of large sizes available to him. If a drive array has 10 disks of 100 GB size, one can represent them as two logical drives of size 700 GB and 300 GB depending upon his needs.
2.4 Mirroring:
A Mirroring is concept used to provide data redundancy so that fault tolerance can finally be achieved. A RAID level that uses mirroring duplicates the same data in two different drives, so that if one drive fails, the data in other is still intact. Mirroring is used in RAID level 1(refer section 3 for RAID levels). Mirroring also provides faster recovery of data as well. However the cost of implementing mirroring is quite high as half of the total number of disks is wasted.
2.5 Striping:
Striping is process of breaking data into multiple stripes and writing and reading them at one go across multiple disks. For example if there's a large file, multiple read cycles need to be employed to read the whole file into memory. Whereas if the file is striped and the data is written across multiple disks, whole of the file can be read in one read cycle. This increases the throughput and improves performance.
Striping can be implemented on byte level as well as block level. The stripe size can be chosen as per the application need. RAID 3 uses byte level striping whereas RAID level 0, 4, 5, 6(refer section 3 for RAID levels) use block level striping.
2.6 Parity:
This is the second technique (first one being mirroring) to provide fault tolerance via redundancy. The parity information is calculated from actual data values and stored in some specific manner along with the data (as in RAID 5, 6) or in separate disk drive (in case of RAID 3, 4). The idea behind using of parity is that - it is extra bit of information that is calculated from the data such that if one of the data bits or blocks get damaged, the original values can be constructed using this additional information.
The parity calculation is done using Logical operation - XOR. The advantage of using XOR is that if you do A XOR B, and then use the result to do XOR B, the result is again A.
For example:
If we have four data elements A, B, C, D and their calculated parity information is P. We can always reproduce one missing element out of five if we know the other four elements. This technique is used in RAID implementations using Parity.
Parity provides better disk utilization than mirroring. When parity is used with striping, it improves performance. However parity has to be calculated for every data that is being written on the disk arrays. To speed up the operation, the RAID controllers normally have computing capability to calculate parity bits for millions of times.
Although parity allows more disk utilization than mirroring but to recover data using parity is more complex than recovery done through mirroring. It's up to the user how he wants the RAID to be implemented and to decide which RAID level would suit his design.
3. RAID LEVELS
RAID levels 0, 1, 3, 4, 5, 6 are discussed below with their advantages and disadvantages. I've skipped RAID level 2 as it's not implemented these days.
3.1. RAID LEVEL 0:
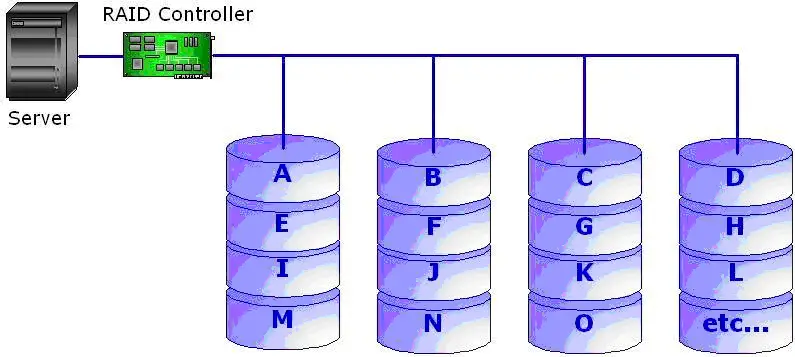
Fig: RAID 0 - Striped Disk Array without Fault Tolerance
RAID 0 implements striping. The data is broken down into blocks and each of the blocks is written on different hard disks in the disk array. RAID 0 requires a minimum of two disk drives to be implemented. Read and write operations are improved as compared to single disk system, since the load is shared across many channel and are done in parallel on the disks. The performance is optimum when there is one controller per disk drive and data stripping is done across multiple controllers. No parity calculation overhead is required. The design is simple and easy to implement. However since there is no redundancy, it doesn't provide fault tolerance. If even one drive fails, data across the drive array will be lost.
3.2. RAID LEVEL 1:
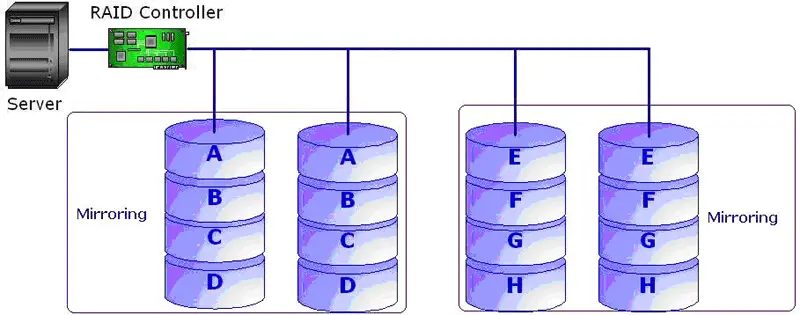
Fig: Mirroring
RAID 1 implements mirroring. It requires a minimum of two disks of equal size to be implemented. If one disk is larger than the other, created RAID device will be of the size of smallest disk. Data is duplicated in both the disks. On disk failure, the recovery is easier as compared to other RAID levels. Data just needs to be copied into the new disk. Write performance is worse than writing on a single disk as multiple writes have to be done, one on each disk on the array. For highest performance the controller should be designed in such a way that it is able to perform two simultaneous read requests - one from each (mirrored) disk. The design is probably the simplest. Major drawback of RAID 1 is that actual disk utilization is only 50% as half of the disks are utilized for mirroring.

